Computer Vision
-
VGG16
- VGG16 has a total of 138 million parameters. The important point to note here is that all the conv kernels are of size 3x3 and maxpool kernels are of size 2x2 with a stride of two.
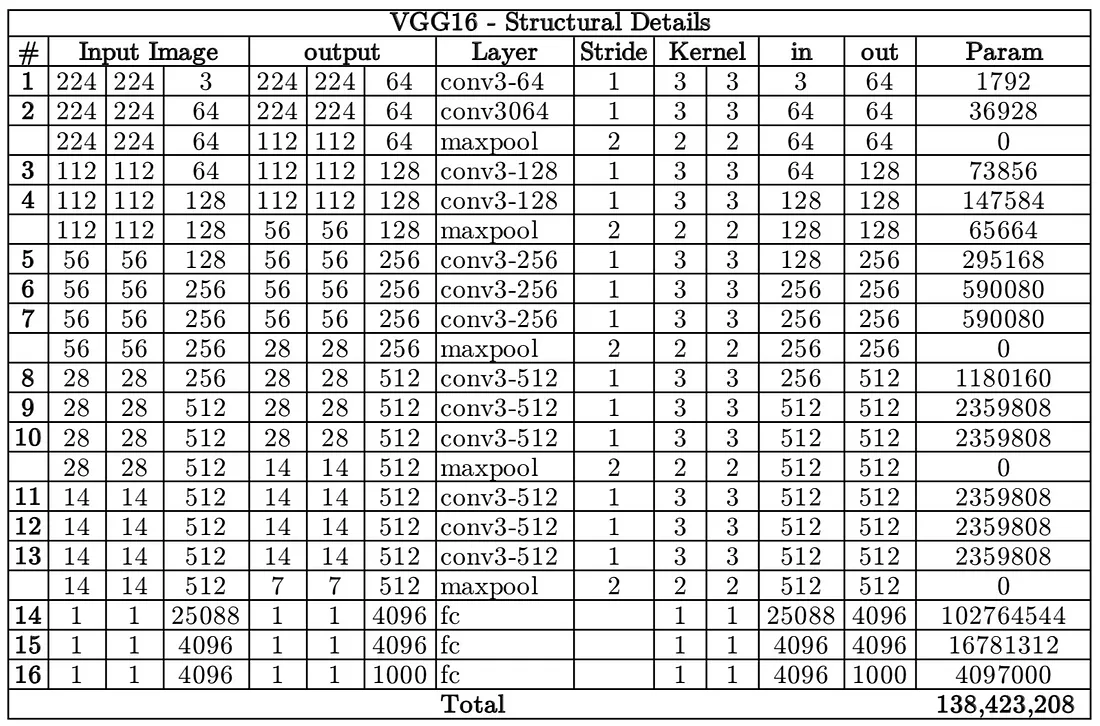
- VGG16 has a total of 138 million parameters. The important point to note here is that all the conv kernels are of size 3x3 and maxpool kernels are of size 2x2 with a stride of two.
-
ResNet
- Resnet18 has around 11 million trainable parameters. It consists of CONV layers with filters of size 3x3 (just like VGGNet). Only two pooling layers are used throughout the network one at the beginning and the other at the end of the network. Identity connections are between every two CONV layers. The solid arrows show identity shortcuts where the dimension of the input and output is the same, while the dotted ones present the projection connections where the dimensions differ.
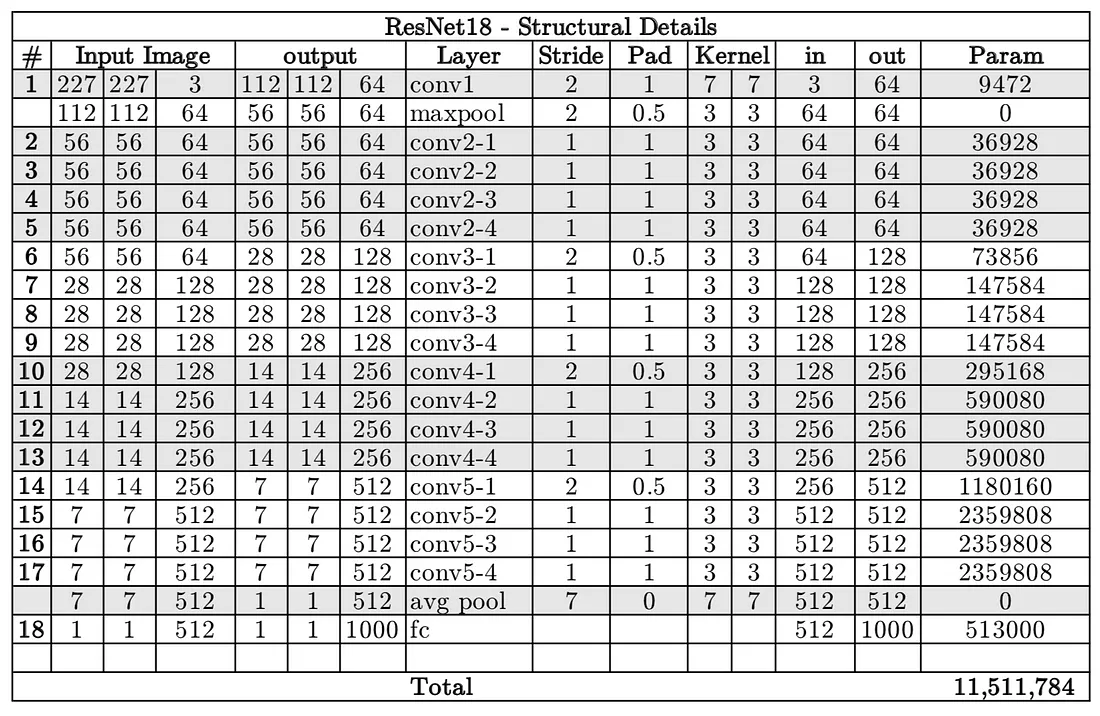
- Resnet18 has around 11 million trainable parameters. It consists of CONV layers with filters of size 3x3 (just like VGGNet). Only two pooling layers are used throughout the network one at the beginning and the other at the end of the network. Identity connections are between every two CONV layers. The solid arrows show identity shortcuts where the dimension of the input and output is the same, while the dotted ones present the projection connections where the dimensions differ.
-
Architecture Differences:
- VGG16: VGG16 is a deep convolutional network with a straightforward and uniform architecture, consisting of 16 layers with very small (3x3) convolution filters. It is known for its simplicity and has been a popular choice for image classification tasks.
- ResNet: ResNet, particularly ResNet-50, uses residual connections that help mitigate the vanishing gradient problem, allowing for the training of much deeper networks. ResNet architectures are typically deeper and more complex than VGG16, which generally results in better feature extraction and higher accuracy in many tasks.
-
Performance:
- Accuracy: ResNet models, due to their depth and residual connections, generally outperform VGG16 in many image recognition tasks, including object detection. They are able to learn more complex features and provide better accuracy.
- Computation and Memory: ResNet models are usually more computationally expensive and require more memory compared to VGG16. This can be a consideration if you have limited computational resources.
-
Application in Object Detection:
- Object detection frameworks such as Faster R-CNN, SSD, and YOLO have utilized both VGG and ResNet as backbone feature extractors. In many cases, ResNet-based models have shown better performance in terms of both precision and recall.
- For instance, Faster R-CNN with a ResNet-50 or ResNet-101 backbone generally performs better than the same framework with a VGG16 backbone.
Practical Considerations:
-
ResNet Advantages:
- Better accuracy and feature representation due to deeper network architecture.
- Residual connections help in training deeper networks, resulting in improved performance.
-
VGG16 Advantages:
- Simpler architecture which can be easier to implement and train.
- Less computationally intensive compared to ResNet.
Conclusion:
In general, ResNet models tend to be better than VGG16 for object detection tasks due to their superior feature extraction capabilities and higher accuracy. However, this comes at the cost of increased computational requirements.
If computational resources are not a constraint, it is recommended to use ResNet (e.g., ResNet-50 or ResNet-101) for better performance in object detection. However, if you need a simpler and less resource-intensive model, VGG16 is still a viable option and can achieve good results.